
{kind=link}
There is new PDF from VMware targeted for VSAN users, architects and IT admins. Recent change in VMware HCL concerning the queue depth of storage adapters (now there are only the ones with queue depth 256 and higher – see the ones are concerned in this VMware KB ) brought more questions concerning availability and performance during resynchronization and rebalance operations.
The paper is called VMware Virtual SAN Data Management Operations and it is a good read because it explains few things that I think many of the folks out there aren't aware. The capacity and performance of VSAN I think that everyone understood so far, how it works during normal operations when everything goes fine.
But when component failure occurs the song is different, because if the storage controller card has queue depth lower than 256 during the resynchronization or rebalance operations the running VMs might experience timeouts and become unresponsive, because the storage controller gets overloaded. Even though VSAN has built-in throttling mechanism which is ON during those operations.
From the HCL update blog post:
Although Virtual SAN has a built-in throttling mechanism for rebuild operations, it is designed to make minimal progress in order to avoid Virtual SAN objects from being exposed to double component failures for a long time. In configurations with low queue-depth controllers, even this minimal progress can cause the controllers to get saturated, leading to high latency and IO time outs.
Given the above scenario, VMware has decided to remove controllers with queue depth of less than 256 from the Virtual SAN compatibility list. While fully functional, these controllers offer too low IO throughput to sustain the performance requirements of most VMware environments.
Back to the paper. This is new for me and I haven't read about it elsewhere. There are two types of hardware failures which can occur in VSAN cluster and depending of the component, VSAN will react differently in each particular case.
Two types of hardware failures can occur in VSAN cluster:
01. Absent Failure – physical network, network card (pNIC), host failure – 60 min delay (configurable parameter ClomRepairDelay – VMware KB 2075456 ) and then resync.
02. Degraded Failure – Magnetic Disk, Flash Device, Storage Controller – immediate resync non configurable!
VMware has in mind that the degraded failure has to do with elements which won't come back online any time soon. Disk drive if becomes unresponsive, then it's because it is dead. It completely makes sense.
Now you see how important is to have storage controller with queue depth higher than 256, but there is also another value to take into account. Which one? Cluster size.
Because the minimum size of VSAN cluster is 3 hosts only, the situation when there is a component failure will affect rebuild as the rebuild will simply won't happens! See the screenshot from the paper.
When a host failure occurs, the remaining two hosts are excluded from the resynchronization operation because the remaining nodes are already hosting objects and components for the affected virtual machines.
That's why it completely makes sense to build clusters with 4 hosts and more.
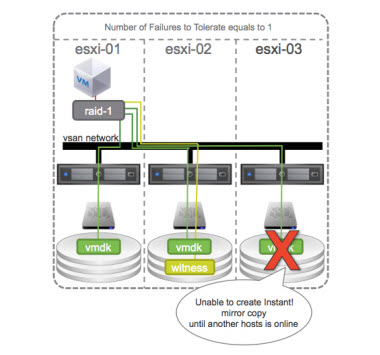
So in this particular case there is no syncing until:
1. The host come back online
2. Another host is added to the VSAN cluster.
VMware Recommendations for VSAN?
To lower resync and rebalance times is best to use 10GbE and storage adapters with queue depth higher than 256 (now mandatory). From the cluster architecture perspective is recommended to create larger clusters with more hosts and more disk groups which allows to lower rebalance and rebuild times as the whole cluster acts as a hot spare disk.
Certainly interesting. The document is available as PDF and I can highly recommend to download as it clears some doubts and gives more arguments when talking about VSAN availability, performance during rebalance and resync operations.
Queue depth of 256 or higher prevents the controller’s IO queue from being overloaded, thus limiting IO operation time outs, high latency, and unresponsive virtual machines.
The author of the paper is Rawlinson Rivera (@punchingclouds).
Source and download: VMware vSphere Blog
HI Dear Vladan
i have 10G network adapter on my vsan but vsan resyncing is very low (for 123GB estimate time is 1 day)
would you help me plz
Hi, if you have a cluster with for instance 10 ESXi, policy RAID-1 with FTT=1, a lot of free space and fail one host, the component will be rebuilt in another host of the cluster. In this case, is it possible another ESXi fail in the cluster? Thanks
Check the latest VSAN documentation. The post might be outdated. Once the rebuilding process finishes. Yes.