
{kind=link}
Again today we continue to explain the basics of VMware vSphere and prepare those ones willing to pass VMware VCP certification exam. In our free guide we cover all topics from VCP-DCV 2021 exam that are listed on the original VMware blueprint that has 80 objectives.
You might want to pass a VCP exam with less work? Hmm, yes, for now, it's still possible as VMware will give you the same title, VCP-DCV 2021 while you'll pass not the 2V0-21.20, but the 2V0-21.19, based on vSphere 6.7.
VMware maintains this exam until June 21st 2021. Note that we have a Free Study Guide for that exam and you can download it as a PDF from our partner.
In today's topic, we'll cover the basics of ESXi clusters. The basics of ESXi cluster is fairly simple. Those ESXi hosts can work together as one. Their resources are put in common and become part fo clusters' resources.

Download FREE Study VCP7-DCV Guide at Nakivo.
- The exam duration is 130 minutes
- The number of questions is 70
- The passing Score is 300
- Price = $250.00
Within a cluster, you can configure services and enable features, such as VMware HA, vMotion, vSphere Distributed Resource Scheduler (DRS) or vSAN. You manage the resources within the vSphere web client UI as single objects.
VMware Enhanced vMotion Compatibility (EVC) when enabled, can help you to make sure that migrations with vMotion do not fail if the CPUs on different hosts within your cluster, are not identical.
With DRS, you can allow automatic resource balancing by using the pooled resources within the cluster. With vSphere HA you basically prevent downtime in the case you have a hardware failure. In fact, when one host fails, the VMs are restarted on other hosts within the cluster automatically. Without the admin needed to do anything.
With vSAN you can use the internal disks of each host and create a shared datastore that is used by your VMs. A minimum 2 hosts is required, with a third host hosting the witness components. Yo u can scale up to 64 hosts.
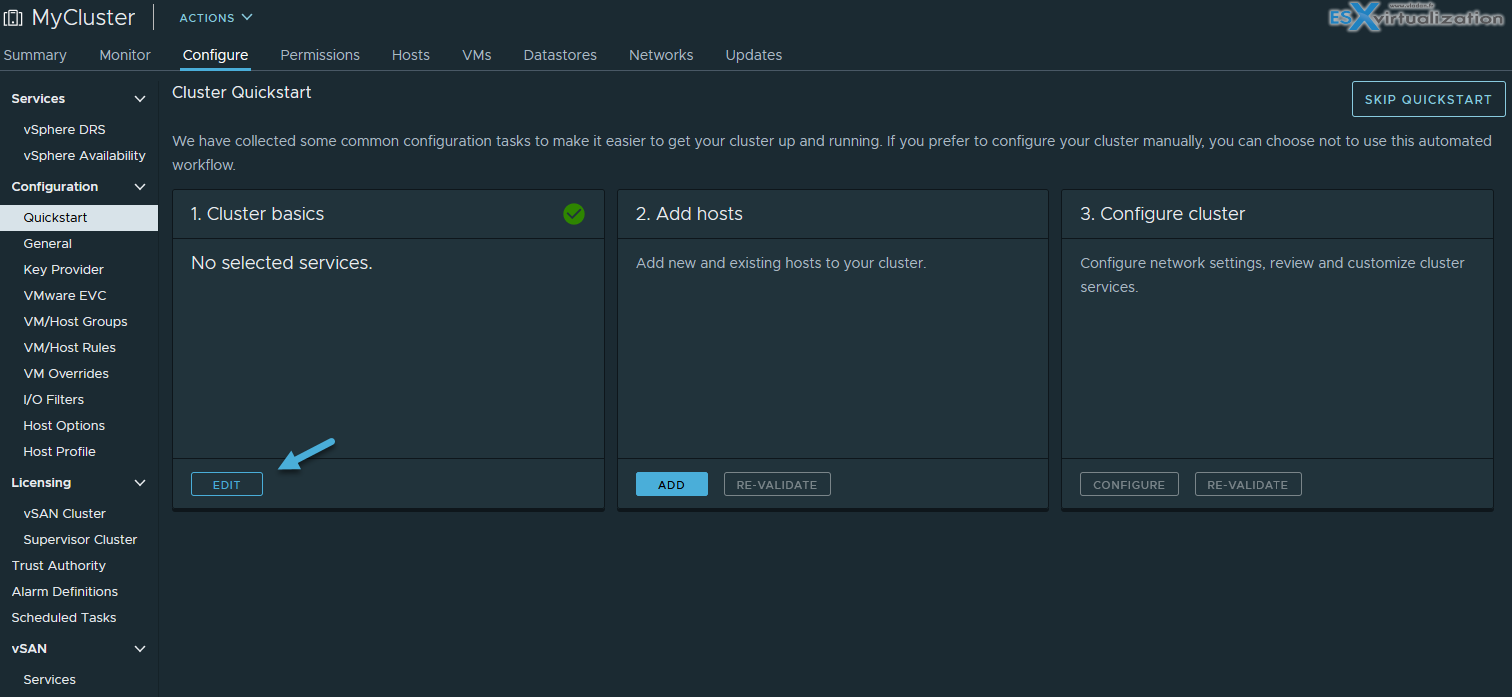
Within your cluster you can choose to manage all hosts in the cluster with a single image. This is new in vSphere 7. With this option, all hosts in a cluster use the same image and that reduces variability between hosts and helps to improve and ensure hardware compatibility. It also simplifies upgrades.
VMware High Availability (HA)
VMware HA continuously monitors all servers in a resource pool and detects server failures. An agent placed on each server maintains a “heartbeat” with the other servers in the resource pool and a loss of “heartbeat” initiates the restart process of all affected virtual machines on other servers.
VMware HA makes sure that sufficient resources are available in the resource pool at all times to be able to restart virtual machines on different physical servers in the event of server failure. Restart of virtual machines is made possible by the Virtual Machine File System (VMFS) clustered file system which gives multiple ESXi Server instances read-write access to the same virtual machine files, concurrently.
Key Features of VMware HA
- Automatic detection of server failures. Automate the monitoring of physical server availability. HA detects server failures and initiates the virtual machine restart without any human intervention.
- Resource checks. Ensure that capacity is always available in order to restart all virtual machines affected by server failure. HA continuously monitors capacity utilization and “reserves” spare
capacity to be able to restart virtual machines.
VMware High Availability (HA) provides easy to use, cost-effective high availability for applications running in virtual machines. In the event of server failure, affected virtual machines are automatically restarted on other production servers with spare capacity.
By activating HA, you basically minimize downtime and IT service disruption while eliminating the need for dedicated stand-by hardware and installation of additional software. You also provide uniform high availability across the entire virtualized IT environment without the cost and complexity of failover solutions tied to either operating systems or specific applications.
How HA works?
When you create a vSphere HA cluster, a single host is automatically elected as the master host. The master host communicates with vCenter Server and monitors the state of all protected virtual machines and of the slave hosts.
When you add a host to a vSphere HA cluster, an agent is uploaded to the host and configured to communicate with other agents in the cluster. Each host in the cluster functions as a master host or a subordinate host (often called “slave”).
HA protects against downtime. Which kind of problems are you protected from?
In a vSphere HA cluster, three types of host failure are detected:
- Failure – A host stops functioning.
- Isolation – A host becomes network isolated.
- Partition – A host loses network connectivity with the master host.
This communication happens through the exchange of network heartbeats every second. When the master host stops receiving these heartbeats from a subordinate host, it checks for host liveness before declaring the host failed. The liveness check that the master host performs is to determine whether the subordinate host is exchanging heartbeats with one of the datastores. See Datastore Heartbeating. Also, the master host checks whether the host responds to ICMP pings sent to its management IP addresses.
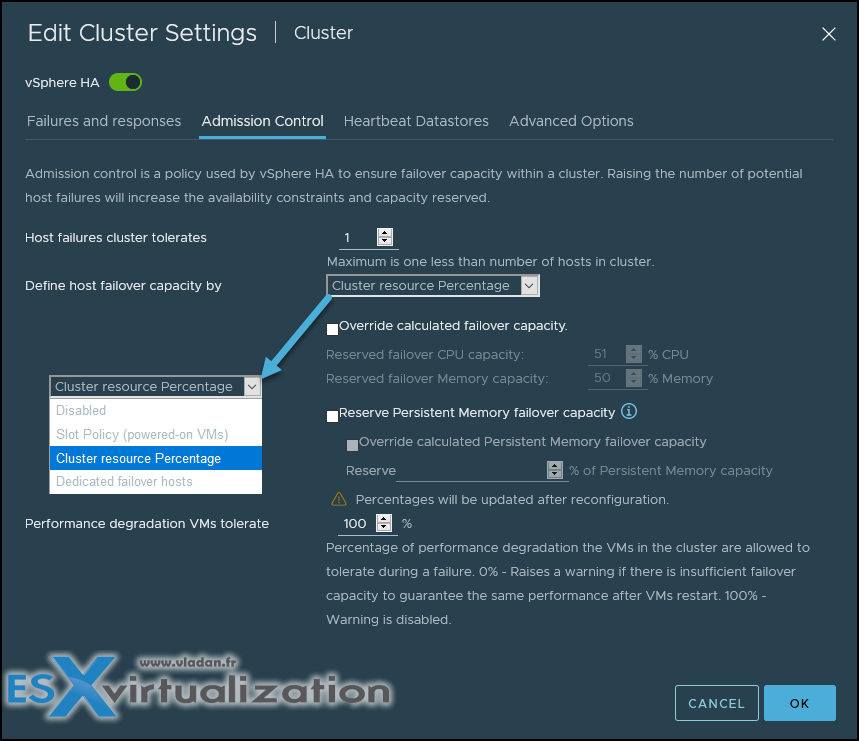
Failures and responses – you can configure how vSphere HA responds to failure conditions on a cluster. There are 4 failure conditions:
- Host – allows you to configure host monitoring and failover on the cluster. (“Disabled” or “Restart VMs” – VMs will be restarted in the order determined by their restart priority).
- Host Isolation – allows you to configure the cluster to respond to host network isolation failures:
- Disabled – No action will be taken on the affected VMs.
- Shut down and restart VMs – All affected VMs will be gracefully shutdown and vSphere HA will attempt to restart the VMs on other hosts online within the cluster.
- Power Off and Restart VMs – All affected VMs will be powered Off and vSphere HA will attempt to restart the VMs on the hosts which are still online.
- VM component protection – datastore with Permanent Device Lost (PDL) and All paths down (APD):
- Datastore with PDL – allows you to configure the cluster to respond to PDL datastore failures.
- Disabled – no action will be taken to the affected VMs.
- Issue events – no action to the affected VMs. Events will be generated only.
- Power Off and restart VMs – All affected VMs will be terminated and vSphere HA will attempt to restart the VMs on hosts that still have connectivity to the datastore.
- Datastore with APD – allows you to configure the cluster to APD datastore failures.
- Disabled – no action will be taken to the affected VMs.
- Issue Events – no action to the affected VMs. Events will be generated only.
- Power Off and restart VMs – All affected VMs will be terminated and vSphere HA will attempt to restart the VMs if another host has connectivity to the datastore.
- Power Off and restart VMs – Aggressive restart policy – All affected VMs will be powered Off and vSphere HA will always attempt to restart VMs.
- Datastore with PDL – allows you to configure the cluster to respond to PDL datastore failures.
- VM and application monitoring – VM monitoring hard restarts of individual VMs if their VM tools heartbeats are not received within a certain time. Application monitoring resets individual VMs if their in-guest heartbeats are not received within a set time.
Admission Control
Admission control is a policy which is used by vSphere HA to make sure that there is enough failover capacity within a cluster.
- Cluster resource Percentage (default) – The configuring workflow for admission control is a little bit simpler. You first define a parameter how many failed hosts you want to tolerate within your cluster, and the system will do the math for you. As default HA cluster admission policy, VMware will use the cluster resource Percentage now. (previously host failures the cluster tolerates policy, was used).
- Override Possible – You can override the default CPU and memory settings if needed. (25% as in previous releases).
Performance degradation Warning message – Previously HA could restart VM, but those would suffer from performance degradation. Now you have a warning message which informs you about it. You’ll be warned if performance degradation would occur after an HA even for a particular VM(s).
0% – Raises a warning if there is insufficient failover capacity to guarantee the same performance after VMs restart.
100% – Warning is disabled
Other then cluster resource percentage policy there are “Slot policy” and “Dedicated failover host” policies.
- Slot policy – the slot size is defined as the memory and CPU resources that satisfy the reservation requirements for any powered-on VMs in the cluster.
- Dedicated Failover Host – You pick a dedicated host which comes into a play when there is a host failure. This host is a “spare” so it does not have running VMs during normal operations. Waste of resources.
Enable/disable vSphere HA settings
To enable vSphere HA, open vSphere Client > Select cluster > Configure > vSphere Availability > Click Edit button.
Find other chapters on the main page of the guide – VCP7-DCV Study Guide – VCP-DCV 2021 Certification,
Thanks for reading and stay tuned for more…
Direct download/buy links:
- VMware vSphere 7.0 Essentials PLUS
- VMware vSphere 7.0 Essentials
- VMware vSphere 7.0 Enterprise PLUS
- vSphere Essentials Per Incident Support
- Upgrade to vSphere Enterprise Plus
- VMware Current Promotions
More posts from ESX Virtualization:
- vSphere 7 U2 Released
- vSphere 7.0 Download Now Available
- vSphere 7.0 Page [All details about vSphere and related products here]
- VMware vSphere 7.0 Announced – vCenter Server Details
- VMware vSphere 7.0 DRS Improvements – What's New
- How to Patch vCenter Server Appliance (VCSA) – [Guide]
- What is The Difference between VMware vSphere, ESXi and vCenter
- How to Configure VMware High Availability (HA) Cluster
Stay tuned through RSS, and social media channels (Twitter, FB, YouTube)
Thank you sir