
{kind=link}
Today's objective is VCP6.5-DCV Objective 7.5 – Troubleshoot HA and DRS Configurations and Fault Tolerance. HA, DRS and FT are core technologies of VMware clusters. It's important to master their requirements, configuration, and troubleshooting.
Check our VCP6.5-DCV Study Guide page which is starting really to take shape and fills up with topics from the Exam Preparation Guide (previously called Exam Blueprint). I highly recommend getting the full vSphere 6.5 documentation set and the latest exam preparation guide (PDF) as well when preparing for the exam. I'm not linking directly in purpose as those PDFs can change URL, but you can find those easily through Google search.
You have a choice to study towards the VCP6-DCV – Exam Number: 2V0-621, ( it has 28 Objectives) or going for the VCP6.5-DCV (Exam Code: 2V0-622) which is few chapters longer (it has 32 Objectives). Both exams are valid for two years, then you have to renew. You can also go further and pass VCAP exam, then VCDX.
Note: VMware released new “bridge” upgrade path. Any VCP who is two versions of the most current available version in the same solution track can upgrade to the latest by only taking one exam. Previously, you would first have to earn the VCP6-DCV (and passing the delta exam) and then upgrade to the VCP6.5-DCV (again, through the delta exam.) Now you can go straight from VCP5 to VCP6.5.
Exam Price: $250 USD, there are 70 Questions (single and multiple answers), passing score 300, and you have 105 min to complete the test.
Check our VCP6.5-DCV Study Guide Page.
You can download your free copy via this link – Download Free VCP6.5-DCV Study Guide at Nakivo.

VCP6.5-DCV Objective 7.5 – Troubleshoot HA and DRS Configurations and Fault Tolerance
- Troubleshoot issues with:
- Explain the DRS Resource Distribution Graph and Target/Current Host Load Deviation
- Explain vMotion Resource Maps
Troubleshoot issues with: DRS workload balancing
There can be a load Imbalance on Cluster. We say that cluster has a load imbalance of resources. Why is that? It's because VMs running different workloads have spikes in CPU and memory demands, so because of uneven resource demands from virtual machines and unequal capacities of hosts, the cluster goes out of balance.
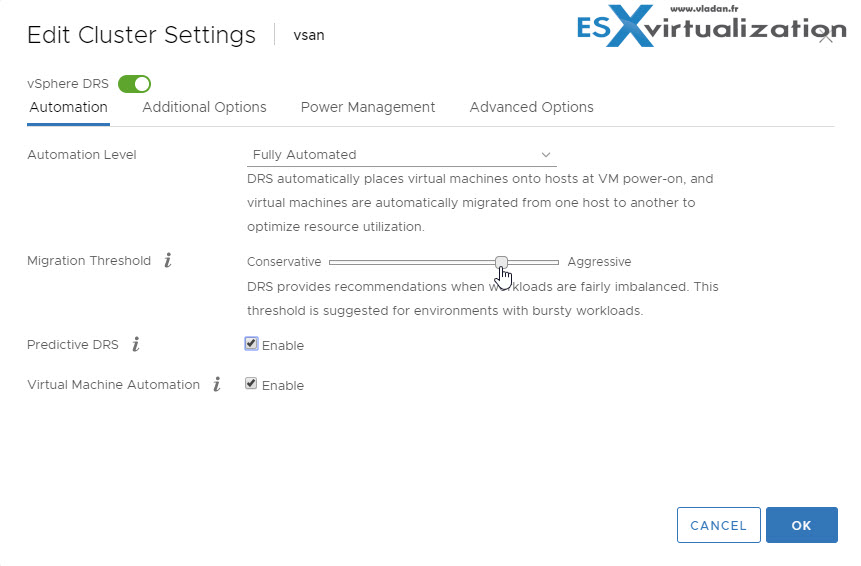
Possible reasons why the cluster has a load imbalance:
- The migration threshold is too high – A higher threshold makes the cluster a more likely candidate for load imbalance.
- VM/VM or VM/Host DRS rules prevent virtual machines from being moved.
- DRS is disabled for one or more virtual machines.
- VM has CD ROM mounted. A device is mounted to one or more virtual machines preventing DRS from moving the virtual machine in order to balance the load.
- VMs are not compatible with the hosts to which DRS would move them. When least one of the hosts in the cluster is incompatible for the virtual machines that would be migrated, DRS won't move that VM. For example, if host A’s CPU is not vMotion-compatible with host B’s CPU, then host A becomes incompatible for powered-on virtual machines running on host B.
- It would be more detrimental to the virtual machine’s performance to move it than for it to run where it is currently located. This may occur when loads are unstable or the migration cost is high compared to the benefit gained from moving the virtual machine.
- vMotion is not enabled or set up for the hosts in the cluster.
- DRS Seldom or Never Performs vMotion Migrations
DRS does not perform vMotion migrations.
DRS never performs vMotion migrations when there are issues in the cluster. Issues like:
- DRS is disabled on the cluster.
- The hosts do not have shared storage.
- The hosts in the cluster do not contain a vMotion network.
- DRS is manual and no one has approved the migration.
DRS seldom performs vMotion when one or more of the following issues is present on the cluster:
- Loads are unstable, or vMotion takes a long time or both. A move is not appropriate.
- DRS seldom or never migrates virtual machines.
- DRS migration threshold is set too high.
DRS moves virtual machines for the following reasons:
- Evacuation of a host that a user requested enter maintenance or standby mode.
- VM/Host DRS rules or VM/VM DRS rules.
- Reservation violations.
- Load imbalance.
- Power management.
HA failover/redundancy, capacity, and network configuration
HA/DRS cluster configuration
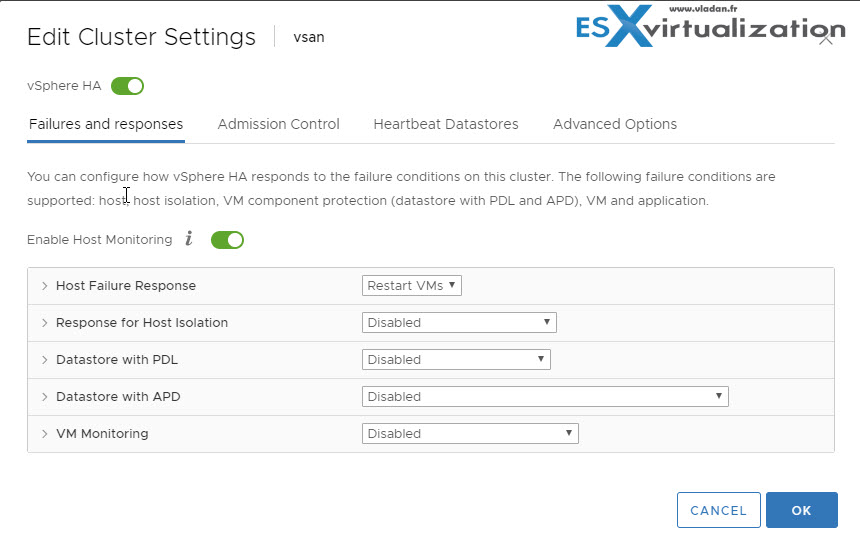
Network Configuration and Maintenance – network maintenance suggestions can help you avoid the accidental detection of failed hosts and network isolation because of dropped vSphere HA heartbeats. Check this:
- When changing the networks that your clustered ESXi hosts are on, suspend the Host Monitoring feature. Changing your network hardware or networking settings can interrupt the heartbeats that vSphere HA uses to detect host failures, which might result in unwanted attempts to fail over virtual machines.
- When you change the networking configuration on the ESXi hosts themselves, for example, adding port groups, or removing vSwitches, suspend Host Monitoring. After you have made the networking configuration changes, you must reconfigure vSphere HA on all hosts in the cluster, which causes the network information to be reinspected. Then re-enable Host Monitoring.
Networks Used for vSphere HA Communications – To identify which network operations might disrupt the functioning of vSphere HA, you must know which management networks are being used for heart beating and other vSphere HA communications.
- On legacy ESX hosts in the cluster, vSphere HA communications travel over all networks that are designated as service console networks. VMkernel networks are not used by these hosts for vSphere HA communications. To contain vSphere HA traffic to a subset of the ESX console networks, use the allowedNetworks advanced option.
- On ESXi hosts in the cluster, vSphere HA communications, by default, travel over VMkernel networks. With an ESXi host, if you want to use a network other than the one vCenter Server uses to communicate with the host for vSphere HA, you must explicitly enable the Management traffic checkbox.
To keep vSphere HA agent traffic on the networks you have specified, configure hosts so vmkNICs used by vSphere HA do not share subnets with vmkNICs used for other purposes. vSphere HA agents send packets using any pNIC that is associated with a given subnet when there is also at least one vmkNIC configured for vSphere HA management traffic. Therefore, to ensure network flow separation, the vmkNICs used by vSphere HA and by other features must be on different subnets.
Network Isolation Addresses – A network isolation address is an IP address that is pinged to determine whether a host is isolated from the network. This address is pinged only when a host has stopped receiving heartbeats from all other hosts in the cluster. If a host can ping its network isolation address, the host is not network isolated, and the other hosts in the cluster have either failed or are network partitioned. However, if the host cannot ping its isolation address, it is likely that the host has become isolated from the network and no failover action is taken.
By default, the network isolation address is the default gateway for the host. Only one default gateway is specified, regardless of how many management networks have been defined. Use the das.isolationaddress[…]advanced option to add isolation addresses for additional networks.
Network Path Redundancy – Use at least two management networks. Single management network ends up being a single point of failure and can result in failovers although only the network has failed. If you have only one management network, any failure between the host and the cluster can cause an unnecessary (or false) failover activity if heartbeat datastore connectivity is not retained during the networking failure. Possible failures include NIC failures, network cable failures, network cable removal, and switch resets. Consider these possible sources of failure between hosts and try to minimize them, typically by providing network redundancy.
Nic Teaming – Using a team of two NICs connected to separate physical switches improves the reliability of a management network. Because servers connected through two NICs (and through separate switches) have two independent paths for sending and receiving heartbeats, the cluster is more resilient. To configure a NIC team for the management network, configure the vNICs in vSwitch configuration for Active or Standby configuration.
The recommended parameter settings for the vNICs are:
- Default load balancing = route based on originating port ID
- Failback = No
After you have added a NIC to a host in your vSphere HA cluster, you must reconfigure vSphere HA on that host.
NIC teaming provides sufficient heartbeat redundancy, but as an alternative, you can create a second management network connection attached to a separate virtual switch. Redundant management networking allows the reliable detection of failures and prevents isolation or partition conditions from occurring because heartbeats can be sent over multiple networks.
When the second management network connection is created, vSphere HA sends heartbeats over both management network connections. If one path fails, vSphere HA still sends and receives heartbeats over the other path.
Using IPv6 Network Configurations – Only one IPv6 address can be assigned to a given network interface used by your vSphere HA cluster. Assigning multiple IP addresses increases the number of heartbeat messages sent by the cluster’s master host with no corresponding benefit.
Best Practices for Interoperability – Observe the following best practices for allowing interoperability between vSphere HA and other features.
vSphere HA and Storage vMotion Interoperability in a Mixed Cluster
In clusters where ESXi 5.x hosts and ESX/ESXi 4.1 or earlier hosts are present and where Storage vMotion is used extensively or Storage DRS is enabled, do not deploy vSphere HA. vSphere HA might respond to a host failure by restarting a virtual machine on a host with an ESXi version different from the one on which the virtual machine was running before the failure. A problem can occur if, at the time of failure, the virtual machine was involved in a Storage vMotion action on an ESXi 5.x host, and vSphere HA restarts the virtual machine on a host with a version earlier than ESXi 5.0. While the virtual machine might power-on, any subsequent attempts at snapshot operations might corrupt the vdisk state and leave the virtual machine unusable.
Best Practices for Cluster Monitoring – Observe the following best practices for monitoring the status and validity of your vSphere HA cluster.
Setting Alarms to Monitor Cluster Changes – When vSphere HA or Fault Tolerance take action to maintain availability, for example, a virtual machine failover, you can be notified about such changes. Configure alarms in vCenter Server to be triggered when these actions occur and have alerts, such as emails, sent to a specified set of administrators.
Some vSphere HA alarms which are available:
- Insufficient failover resources (a cluster alarm)
- Cannot find master (a cluster alarm)
- Failover in progress (a cluster alarm)
- Host HA status (a host alarm)
- VM monitoring error (a virtual machine alarm)
- VM monitoring action (a virtual machine alarm)
- Failover failed (a virtual machine alarm)
vMotion/Storage vMotion configuration and/or migration
When vMotion request is sent to the vCenter Server, a call is sent to vCenter Server requesting the live migration of a virtual machine to another host. This call may be issued through the VMware vSphere Web Client, VMware vSphere Client or through an API call.
vCenter Server sends the vMotion request to the destination ESXi host – a request is sent to the destination ESXi host by vCenter Server to notify the host for an incoming vMotion. This step also validates if the host can receive a vMotion. If a vMotion is allowed on the host, the host replies to the request allowing the vMotion to continue. If the host is not configured for vMotion, the host replies to the request disallowing the vMotion, resulting in a vMotion failure.
Possible issues:
- Ensure that vMotion is enabled on all ESX/ESXi hosts.
- Determine if resetting the Migrate.Enabled setting on both the source and destination ESX or ESXi hosts addresses the vMotion failure.
- Verify that VMkernel network connectivity exists using vmkping.
- Verify that VMkernel networking configuration is valid.
- Verify that Name Resolution is valid on the host.
- Verify if the ESXi/ESX host can be reconnected or if reconnecting the ESX/ESXi host resolves the issue.
- Verify that you do not have two or more virtual machine swap files in the virtual machine directory.
- If you are migrating a virtual machine to or from a host running VMware ESXi below version 5.5 Update 2.
vCenter Server sends the vMotion request to the source ESXi host to prepare the virtual machine for migration – Here, request is made to the source ESXi host by vCenter Server to notify the host for an incoming vMotion. This step validates if the host can send a vMotion. If a vMotion is allowed on the host, the host replies to the request allowing the vMotion to continue. If the host is not configured for vMotion, the host will reply to the request disallowing the vMotion, resulting in a vMotion failure.
Once the vMotion task has been validated, the configuration file for the virtual machine is placed into read-only mode and closed with a 90 second protection timer. This prevents changes to the virtual machine while the vMotion task is in progress.
Possible issues:
- Ensure that vMotion is enabled on all ESX/ESXi hosts.
- Determine if resetting the Migrate.Enabled setting on both the source and destination ESX or ESXi hosts addresses the vMotion failure. For more information.
- Verify that VMkernel network connectivity exists using vmkping. For more information.
- Verify that VMkernel networking configuration is valid. For more information.
- Verify that Name Resolution is valid on the host. For more information.
- Verify if the ESXi/ESX host can be reconnected or if reconnecting the ESX/ESXi host resolves the issue.
vCenter Server initiates the destination host virtual machine – the destination host creates, registers and powers on a new virtual machine. The virtual machine is powered on to a state that allows the virtual machine to consume resources and prepares it to receive the virtual machine state from the source host. During this time a world ID is generated that is sent to the source host as the target virtual machine for the vMotion.
Possible issues:
- Verify that the required disk space is available.
- Verify that time is synchronized across environment.
- Verify that hostd is not spiking the console.
- Verify that valid limits are set for the virtual machine being vMotioned.
- Verify if the ESXi/ESX host can be reconnected or if reconnecting the ESX/ESXi host resolves the issue.
vCenter Server initiates the source host virtual machine – The source host begins to migrate the memory and running state of the source virtual machine to the destination virtual machine. This information is transferred using VMkernel ports configured for vMotion. Additional resources are allocated for the destination virtual machine and additional helper worlds are created. The memory of the source virtual machine is transferred using checkpoints.
After the memory and virtual machine state is completed, a stun of the source virtual machine occurs to copy any remaining changes that occurred during the last checkpoint copy. Once this is complete the destination virtual machine resume as the primary machine for the virtual machine that is being migrated.
Possible issues:
If Jumbo Frames are enabled (MTU of 9000) (9000 -8 bytes (ICMP header) -20 bytes (IP header) for a total of 8972), ensure that vmkping is using the command:
vmkping -d -s 8972 destinationIPaddress
You may experience problems with the trunk between two physical switches that have been misconfigured to an MTU of 1500.
- Verify that valid limits are set for the virtual machine being vMotioned.
- Verify the virtual hardware is not out of date.
- This issue may be caused by SAN configuration. Specifically, this issue may occur if zoning is set up differently on different servers in the same cluster.
Verify and ensure that the log.rotateSize parameter in the virtual machine’s configuration file is not set to a very low value. - If you are migrating a 64-bit virtual machine, verify that the VT option is enabled on both the source and destination host. For more information.
Verify that there are no issues with the shared storage or networking. - If you are using NFS storage, verify if the VMFS volume containing the VMDK file of a virtual machine being migrated is on an NFS datastore and the datastore is not mounted differently on both the source and destination.
- If you are using VMware vShield Endpoint, verify the vShield Endpoint LKM is installed on the ESX/ESXi hosts to which you are trying to vMotion the virtual machine.
Fault Tolerance configuration and failover issues
How to resolve FT problems.
- Hardware Virtualization Not Enabled – You must enable Hardware Virtualization (HV) before you use vSphere Fault Tolerance.
- Compatible Hosts Not Available for Secondary VM – If you power on a virtual machine with Fault Tolerance enabled and no compatible hosts are available for its Secondary VM, you might receive an error message.
- Secondary VM on Overcommitted Host Degrades Performance of Primary VM – If a Primary VM appears to be executing slowly, even though its host is lightly loaded and retains idle CPU time, check the host where the Secondary VM is running to see if it is heavily loaded.
- Increased Network Latency Observed in FT Virtual Machines – If your FT network is not optimally configured, you might experience latency problems with the FT VMs.
- Some Hosts Are Overloaded with FT Virtual Machines – You might encounter performance problems if your cluster’s hosts have an imbalanced distribution of FT VMs.
- Losing Access to FT Metadata Datastore – Access to the Fault Tolerance metadata datastore is essential for the proper functioning of an FT VM. Loss of this access can cause a variety of problems.
- Turning On vSphere FT for Powered-On VM Fails – If you try to turn on vSphere Fault Tolerance for a powered-on VM, this operation can fail.
- FT Virtual Machines not Placed or Evacuated by vSphere DRS – FT virtual machines in a cluster that is enabled with vSphere DRS do not function correctly if Enhanced vMotion Compatibility (EVC) is currently disabled.
- Fault-Tolerant Virtual Machine Failovers – A Primary or Secondary VM can fail over even though its ESXi host has not crashed. In such cases, virtual machine execution is not interrupted, but redundancy is temporarily lost. To avoid this type of failover, be aware of some of the situations when it can occur and take steps to avoid them.
Explain the DRS Resource Distribution Graph and Target/Current Host Load Deviation
VMware vSphere has DRS resource distribution graph which shows CPU or Memory metric for each of the hosts in the cluster. The DRS cluster is load balanced when each of the hosts’ level of consumed resources is equivalent to all the other nodes in the cluster.
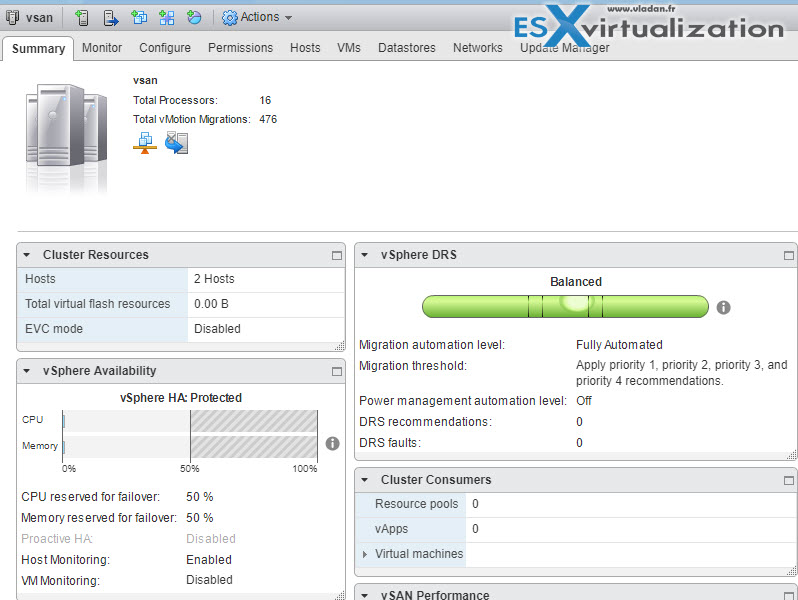
The objective for DRS is not to balance the load perfectly across every host. Rather, DRS monitors the resource demand and works to ensure that every VM is getting the resources entitled. When DRS determines that a better host exists for the VM, it makes a recommendation to move that VM.
Explain vMotion Resource Maps
vMotion resource maps give us a visual representation of hosts, datastores, and networks associated with the selected virtual machine. It indicates which hosts in the cluster or datacenter are compatible with the VM and shows potential migration targets.
The host must:
- Connect to all the same datastores as the virtual machine.
- Connect to all the same networks as the virtual machine.
- Have compatible software with the virtual machine.
- Have a compatible CPU with the virtual machine.
We heavily used the VMware vSphere documentation set to put this together. You should download the latest version of the documentation set in PDF format in order to have the latest document to study as well. Our guide cannot simply cover everything so we must make some choice. Visit our VCP6.5-DCV study page guide (link below) and stay tuned for more articles on ESX Virtualization blog.
More from ESX Virtualization
- VCP6.5-DCV Study Guide
- ESXi Lab
- vSphere 6.5
- Configuration Maximums
- .VMware Virtual Hardware Performance Optimization Tips
Stay tuned through RSS, and social media channels (Twitter, FB, YouTube)