
Today we'll cover another chapter from latest VMware certification exam VCP6.5-DCV. Our study guide page is taking shape here: VCP6.5-DCV Study guide. Today's topic: VCP6.5-DCV Objective 9.1 – Configure vSphere HA Cluster Features.
VMware latest certification exam VCP6.5-DCV has 70 Questions (single and multiple choices), passing score 300, and you have 105 min to complete the test. You can still take the older exam, VCP6-DCV which seems less demanding. It has 4 chapters less. But probably the best choice is to go for the latest exam.
Check our VCP6.5-DCV Study Guide Page. Take this as an additional resource to learn from. You can combine the traditional study PDFs, Books, Pluralsight training with our guide.
You can download your free copy via this link – Download Free VCP6.5-DCV Study Guide at Nakivo.

VCP6.5-DCV Objective 9.1 – Configure vSphere HA Cluster Features
- Modify vSphere HA cluster settings
- Configure a network for use with HA heartbeats
- Apply an admission control policy for HA
- Enable/disable vSphere HA settings
- Configure different heartbeat datastores for an HA cluster
- Apply virtual machine monitoring for a cluster
- Configure Virtual Machine Component Protection (VMCP) settings
- Implement vSphere HA on a vSAN cluster
- Explain how vSphere HA communicates with Distributed Resource Scheduler and Distributed Power Management
Modify vSphere HA cluster settings
As you know, vSphere HA provides high availability for virtual machines by pooling the virtual machines and the hosts they reside on into a cluster. Hosts in the cluster are monitored and in the event of a failure, the virtual machines on a failed host are restarted on alternate hosts. There is a small service interruption, the time to restart the VMs.
Failures and responses – you can configure how vSphere HA responds to failure conditions on a cluster. There are 4 failure conditions:
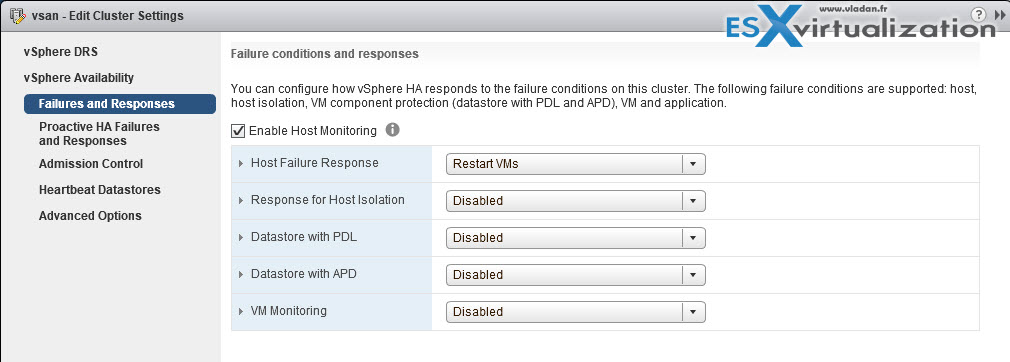
- Host – allows you to configure host monitoring and failover on the cluster. (“Disabled” or “Restart VMs” – VMs will be restarted in the order determined by their restart priority).
- Host Isolation – allows you to configure the cluster to respond to host network isolation failures:
- Disabled – No action will be taken on the affected VMs.
- Shut down and restart VMs – All affected VMs will be gracefully shutdown and vSphere HA will attempt to restart the VMs on other hosts online within the cluster.
- Power Off and Restart VMs – All affected VMs will be powered Off and vSphere HA will attempt to restart the VMs on the hosts which are still online.
- VM component protection – datastore with Permanent Device Lost (PDL) and All paths down (APD):
- Datastore with PDL – allows you to configure the cluster to respond to PDL datastore failures.
- Disabled – no action will be taken to the affected VMs.
- Issue events – no action to the affected VMs. Events will be generated only.
- Power Off and restart VMs – All affected VMs will be terminated and vSphere HA will attempt to restart the VMs on hosts that still have connectivity to the datastore.
- Datastore with APD – allows you to configure the cluster to APD datastore failures.
- Disabled – no action will be taken to the affected VMs.
- Issue Events – no action to the affected VMs. Events will be generated only.
- Power Off and restart VMs – All affected VMs will be terminated and vSphere HA will attempt to restart the VMs if another host has connectivity to the datastore.
- Power Off and restart VMs – Aggressive restart policy – All affected VMs will be powered Off and vSphere HA will always attempt to restart VMs.
- Datastore with PDL – allows you to configure the cluster to respond to PDL datastore failures.
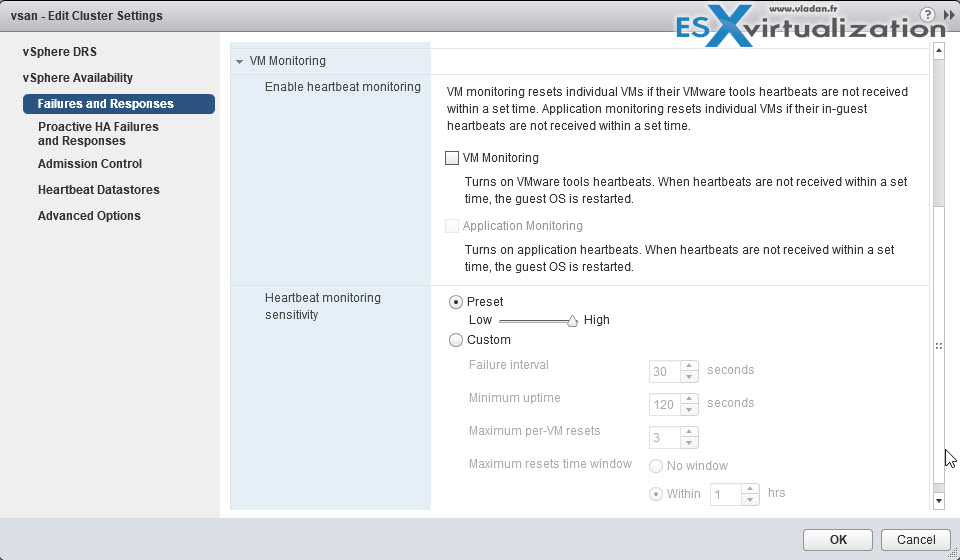
- VM and application monitoring – VM monitoring hard restarts of individual VMs if their VM tools heartbeats are not received within a certain time. Application monitoring resets individual VMs if their in-guest heartbeats are not received within a set time.
{kind=link}
Configure a network for use with HA heartbeats
VMware recommends redundant management network connections for vSphere HA.
On legacy ESX hosts in the cluster, vSphere HA communications travel over all networks that are designated as service console networks. VMkernel networks are not used by these hosts for vSphere HA communications. To contain vSphere HA traffic to a subset of the ESX console networks, use the allowedNetworks advanced option.
On ESXi hosts in the cluster, vSphere HA communications, by default, travel over VMkernel networks. With an ESXi host, if you want to use a network other than the one vCenter Server uses to communicate with the host for vSphere HA, you must explicitly enable the Management traffic checkbox.
To keep vSphere HA agent traffic on the networks you have specified, configure hosts so vmkNICs used by vSphere HA do not share subnets with vmkNICs used for other purposes. vSphere HA agents send packets using any pNIC that is associated with a given subnet when there is also at least one vmkNIC configured for vSphere HA management traffic. Therefore, to ensure network flow separation, the vmkNICs used by vSphere HA and by other features must be on different subnets.
Network Isolation Addresses – A network isolation address is an IP address that is pinged to determine whether a host is isolated from the network. This address is pinged only when a host has stopped receiving heartbeats from all other hosts in the cluster. If a host can ping its network isolation address, the host is not network isolated, and the other hosts in the cluster have either failed or are network partitioned. However, if the host cannot ping its isolation address, it is likely that the host has become isolated from the network and no failover action is taken.
By default, the network isolation address is the default gateway for the host. Only one default gateway is specified, regardless of how many management networks have been defined. Use the das.isolationaddress[…] advanced option to add isolation addresses for additional networks.
Network Path Redundancy – Network path redundancy between cluster nodes is important for vSphere HA reliability. A single management network ends up being a single point of failure and can result in failovers although only the network has failed. If you have only one management network, any failure between the host and the cluster can cause an unnecessary (or false) failover activity if heartbeat datastore connectivity is not retained during the networking failure. Possible failures include NIC failures, network cable failures, network cable removal, and switch resets. Consider these possible sources of failure between hosts and try to minimize them, typically by providing network redundancy.
The first way you can implement network redundancy is at the NIC level with NIC teaming. Using a team of two NICs connected to separate physical switches improves the reliability of a management network. Because servers connected through two NICs (and through separate switches) have two independent paths for sending and receiving heartbeats, the cluster is more resilient. To configure a NIC team for the management network, configure the vNICs in vSwitch configuration for Active or Standby configuration. The recommended parameter settings for the vNICs are:
Default load balancing = route based on originating port ID
Failback = No
After you have added a NIC to a host in your vSphere HA cluster, you must reconfigure vSphere HA on that host.
In most implementations, NIC teaming provides sufficient heartbeat redundancy, but as an alternative, you can create a second management network connection attached to a separate virtual switch.
Redundant management networking allows the reliable detection of failures and prevents isolation or partition conditions from occurring because heartbeats can be sent over multiple networks. The original management network connection is used for network and management purposes.
When the second management network connection is created, vSphere HA sends heartbeats over both management network connections. If one path fails, vSphere HA still sends and receives heartbeats over the other path.
Apply an admission control policy for HA
Admission control is a policy which is used by vSphere HA to make sure that there is enough failover capacity within a cluster.
- The new default is Cluster resource Percentage – The configuring workflow for admission control is a little bit simpler. You first define a parameter how many failed hosts you want to tolerate within your cluster, and the system will do the math for you. As default HA cluster admission policy, VMware will use the cluster resource Percentage now. (previously host failures the cluster tolerates policy, was used).
- Override Possible – You can override the default CPU and memory settings if needed. (25% as in previous releases).
Performance degradation Warning message – Previously HA could restart VM, but those would suffer from performance degradation. Now you have a warning message which informs you about it. You’ll be warned if performance degradation would occur after an HA even for particular VM(s).
0% – Raises a warning if there is insufficient failover capacity to guarantee the same performance after VMs restart.
100% – Warning is disabled
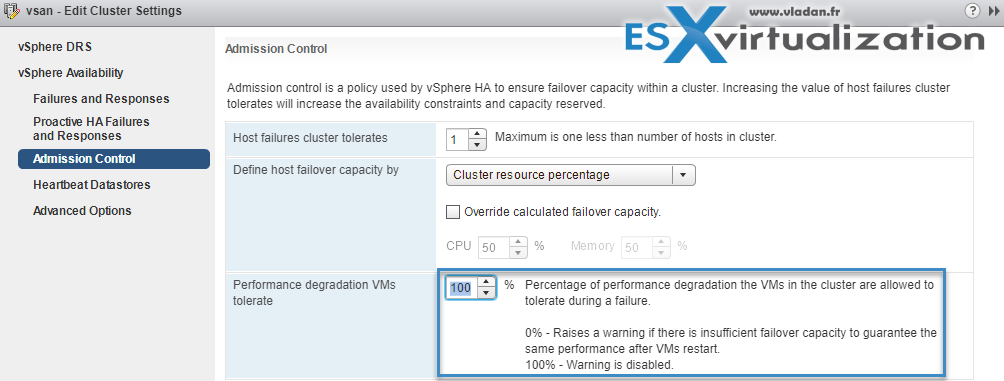
Other then cluster resource percentage policy there are “Slot policy” and “Dedicated failover host” policies.
Slot policy – the slot size is defined as the memory and CPU resources that satisfy the reservation requirements for any powered-on VMs in the cluster.
Dedicated Failover Host – You pick a dedicated host which comes into a play when there is a host failure. This host is a “spare” so it does not have running VMs during normal operations. Waste of resources.
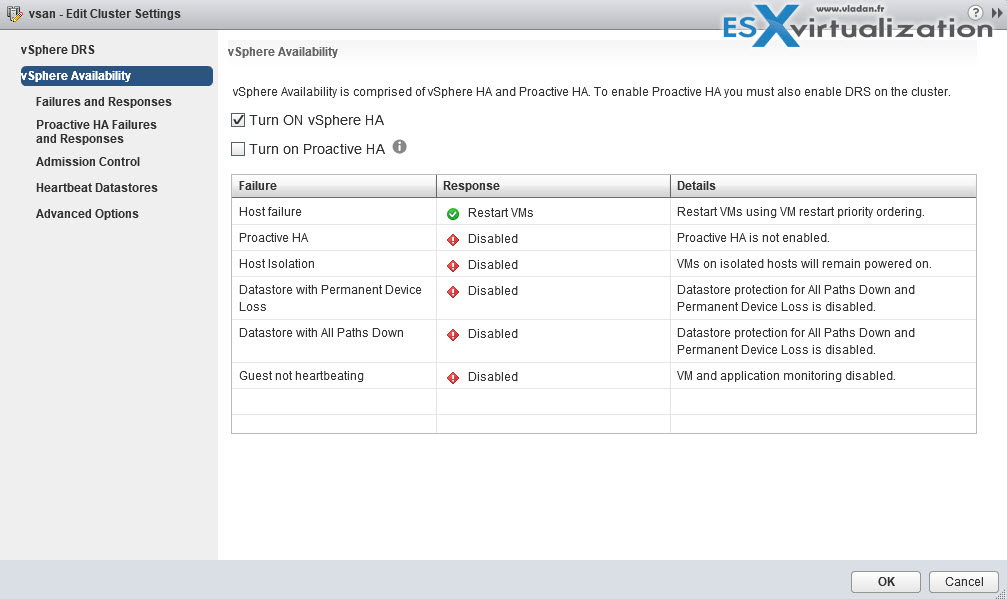
Enable/disable vSphere HA settings
To enable vSphere HA, open vSphere Client > Select cluster > Configure > vSphere Availability > Click Edit button.
To enable/disable individual settings, select the setting on the left, to activate/deactivate on the right.
Check above for “failure and responses” section.
Configure different heartbeat datastores for an HA cluster
In case the Master cannot communicate with a slave (don’t receive the heartbeats), but the heartbeat datastore answers, the server is still working. So if that’s the case, the host is partitioned from the network or isolated. The Datastore heartbeat function helps greatly to determine the difference between host which failed and host that has just been isolated from others.
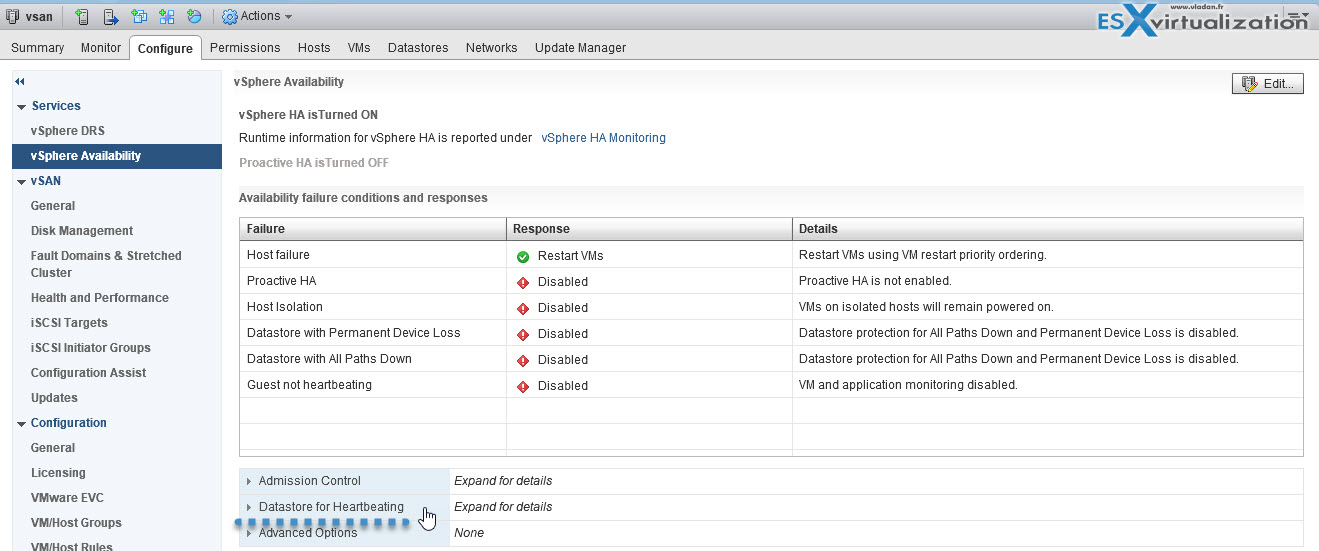
Figure 1: Select cluster > Configure > vSphere Availability > Datastore for hearbeating.
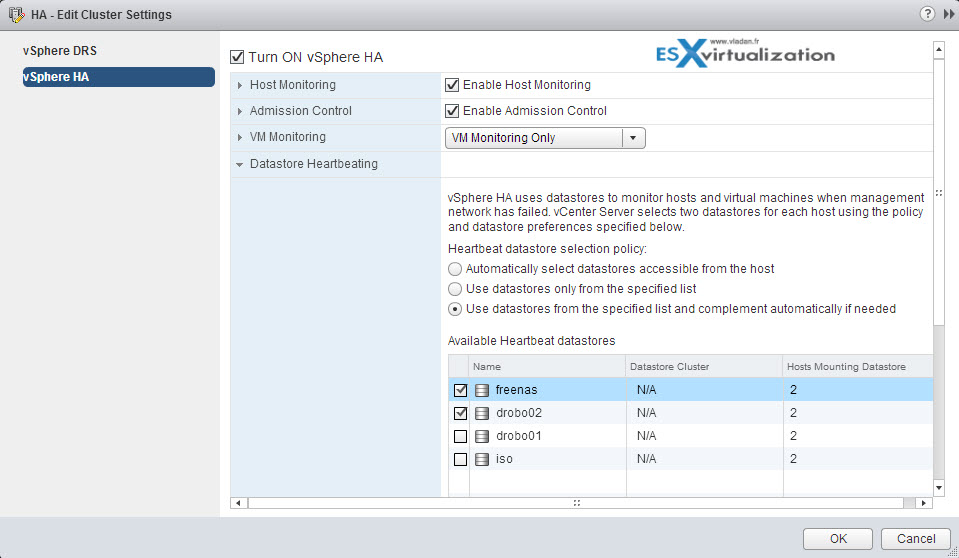
vCenter automatically selects at least two datastores from the shared datastores. It’s preferable to have VMware Datastore heartbeating selected on every NAS/SAN device you have. In my example above I have two shared datastores checked, each on a different storage device.
Apply virtual machine monitoring for a cluster
Idem as above, section “Modify vSphere HA cluster settings”.
Configure Virtual Machine Component Protection (VMCP) settings
VMCP can be found also at the “Modify vSphere HA cluster settings” section.
VMCP settings are settings for datastores with Permanent Device Lost (PDL) and All paths down (APD).
Implement vSphere HA on a vSAN cluster
To use vSphere HA with Virtual SAN, you must be aware of certain considerations and limitations for the interoperability of these two features.
ESXi Requirements:
- All the cluster's ESXi hosts must be version 5.5 or later.
- The cluster must have a minimum of three ESXi hosts.
Virtual SAN has its own network. If Virtual SAN and vSphere HA are enabled for the same cluster, the HA interagent traffic flows over this storage network rather than the management network. vSphere HA uses the management network only if Virtual SAN is disabled. vCenter Server chooses the appropriate network if vSphere HA is configured on a host.
You can enable Virtual SAN only if vSphere HA is disabled. If you change the Virtual SAN network configuration, the vSphere HA agents do not automatically pick up the new network settings. So you must:
Disable host monitoring for HA cluster > Make vSAN network changes > Right-click all hosts in the vSAN cluster > Reconfigure for vSphere HA. > Re-enable Host Monitoring for HA cluster.
Capacity Reservation Settings – When you reserve capacity for your vSphere HA cluster with an admission control policy, you must coordinate this seĴing with the corresponding Virtual SAN seĴing that ensures data accessibility on failures. Specifically, the Number of Failures Tolerated settng in the Virtual SAN rule set must not be lower than the capacity that the vSphere HA admission control settng reserved.
For example, if the Virtual SAN rule set allows for only two failures, the vSphere HA admission control policy must reserve capacity that is equivalent to only one or two host failures. If you are using the Percentage of Cluster Resources Reserved policy for a cluster that has eight hosts, you must not reserve more than 25% of the cluster resources. In the same cluster, with the Host Failures Cluster Tolerates policy, the setting must not be higher than two hosts.
If vSphere HA reserves less capacity, failover activity might be unpredictable. Reserving too much capacity overly constrains the powering on of virtual machines and intercluster vSphere vMotion migrations.
Explain how vSphere HA communicates with Distributed Resource Scheduler and Distributed Power Management
Using vSphere HA with Distributed Resource Scheduler (DRS) combines automatic failover with load balancing. This combination can result in a more balanced cluster after vSphere HA has moved virtual machines to different hosts. When vSphere HA performs failover and restarts virtual machines on different hosts, its first priority is the immediate availability of all virtual machines. After the virtual machines have been restarted, those hosts on which they were powered on might be heavily loaded, while other hosts are comparatively lightly loaded.
vSphere HA uses the virtual machine's CPU and memory reservation and overhead memory to determine if a host has enough spare capacity to accommodate the virtual machine.
In a cluster using DRS and vSphere HA with admission control turned on, virtual machines might not be evacuated from hosts entering maintenance mode. This behavior occurs because of the resources reserved for restarting virtual machines in the event of a failure. You must manually migrate the virtual machines off of the hosts using vMotion.
Note: This topic used partly the “vSphere ESXi vCenter server 6.5 availability” PDF.
So that was another chapter today. There is more to come, more to study. Check our VCP6.5-DCV Study Guide Page.
More from ESX Virtualization:
- What is The Difference between VMware vSphere, ESXi, and vCenter
- VMware vSphere Standard vs Enterprise Plus
- VMware Virtual Hardware Performance Optimization Tips
- How VMware HA Works?
- Configuration Maximums
- What is VMware Stretched Cluster?
Stay tuned through RSS, and social media channels (Twitter, FB, YouTube)