
{kind=link}
With Flash storage around gaining popularity, it might be interesting to see not only if the performance is what's should be but also the health of disks whether the're magnetic or Flash drives. I was looking on checking somehow the S.M.A.R.T values. There are two ways to check it on VMware ESXi, and it can be done through SSH (possibly also through PowerCLI, but I'm not an expert).
So let's see what we'll find by looking through the SSH. First, connect via SSH to your ESXi box and enter this command:
esxcli storage core device list
This shows the list of the hard drives and Flash devices attached to this box (including volumes attached via iSCSI, so make sure to look for local disk. Then you can append the hardware id of the particular drive at the end like this:
esxcli storage core device smart get -d naa.5e83a975f4156eb1
As an output you'll see this:
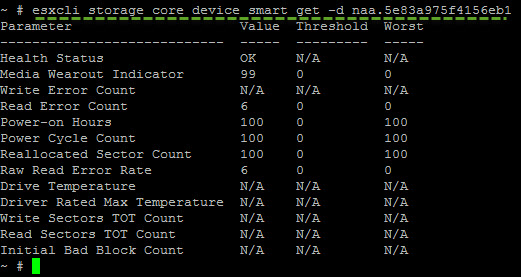
You can obtain the same results for all disks in once by invoking a script which lays in this folder which is a part of the VMware support:
The path is this:
/usr/lib/vmware/vm-support/bin
and here is the output…
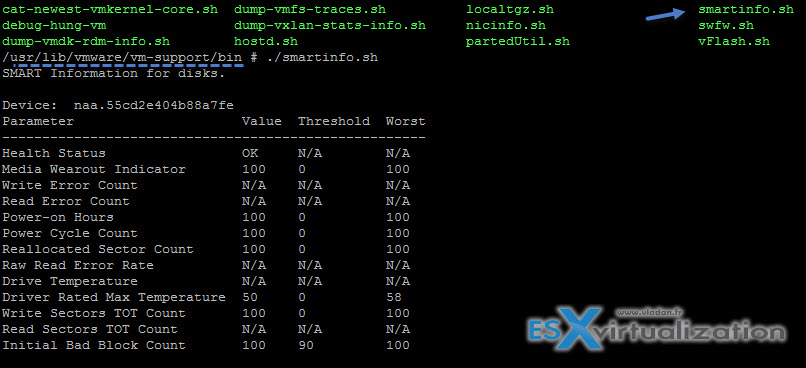
If you're on physical box, laptop or workstation, you might also check out this utility called HD Sentinel which I reviewed a while back. It's an utility which can tell you BEFORE you'll start experiencing problems with your SSD or HDD.
The smartinfo.sh script does not surface any of the S.M.A.R.T info into the GUI (Windows or web based clients), but it's (for now) only an informative utility for checking the state of the SSDs. I'd guess that we might see some more informations here as the storage vendors could integrate the known values of certified flash devices which would show (through the UI) for example how many days (hours) can particular devices run without risk or even more detailed informations. For example how many reserved space is left on the SSD as some manufacturers uses the unused space to keep it as a reservation when the SSD starts to deteriorate.
I found it useful to extract the model and UID from the list so I could easily cut and past the UID in the “esxcli storage core device smart get -d ” command
~ # esxcli storage core device list | egrep ‘Model|UID’
Hello!
Is there any way to check disk SMART values when they are in RAID 1 (IBM server with 5.5u2)?
when I list with smartinfo.sh it says for every value N/A
thanks 🙂
I don’t think so. I believe that the server hardware vendor shall provide such a tools, if installed with the OEM customized ISO the CIM providers shall perhaps show that values through vSphere client. (Hardware status tab)
Hi Vladan!
Thanks for reply, i don’t have ibm’s customized iso, yeah, I’ve already checked the hardware tab, but there are everything “OK”, I’ll check it with linux, see you soon 🙂
of course, under linux is everything went fine with smartctl
if anybody will have a same issue, just boot “any” livecd and issue below command like this:
smartctl -a -d megaraid,X /dev/sdY
where X is your disk number in raid array and Y is your disk letter that give your raid controller (in my case /dev/sda)
Hi
output of command for my server “esxcli storage core device smart get -d naa.5e83a975f4156eb1” show N/A for all parameters.
i use HP VMware ESXi 5.5 Bundle on HP DL380 G6.
I’ve been playing around and testing ” smart get -d” and smartinfo.sh and i have some bad news.
Don’t relay too much on this, since i have a disk (two actually – Hitachi and Seagate) with SMART status warning (reallocated sector count > 0), and both commands don’t report any problem for the disks.
Reallocated sectors is for me first and most common sign of disk failure. Failing to catch does signs makes this smart information from host hardly usable and certainly not dependable.
host:
Device: t10.ATA_____ST9320325AS_________________________________________6VD042RE
Parameter Value Threshold Worst
-----------------------------------------------------
Health Status OK N/A N/A
Media Wearout Indicator N/A N/A N/A
Write Error Count N/A N/A N/A
Read Error Count 100 6 96
Power-on Hours 68 0 68
Power Cycle Count 100 20 37
Reallocated Sector Count 100 36 100
Raw Read Error Rate 100 6 96
Drive Temperature 27 0 60
Driver Rated Max Temperature 73 45 40
Write Sectors TOT Count 200 0 200
Read Sectors TOT Count N/A N/A N/A
Initial Bad Block Count 100 99 100
Client on PC (Crystal Disk Info):
[ST9320325AS6VD042REFIRST]
Date=2015/03/30 15:22:59
HealthStatus=2
Temperature=26
PowerOnCount=290
01=100
03=99
04=100
05=100
ReallocatedSectorsCount=3
07=78
09=68
0A=100
0C=100
B8=100
BB=1
BC=100
BD=100
BE=74
BF=100
C0=100
C1=1
C2=26
C3=69
C5=100
CurrentPendingSectorCount=5
C6=100
UncorrectableSectorCount=5
C7=200
FE=100
Another thing is SSDs and Media Wearout Indicator.
Result N/A for:
Corsair_Neutron_GTX
Samsung_SSD_840_PRO
Samsung_SSD_850_PRO
Crucial M42DCT128M4SSD2 (tested since it’s at 82% if that would make any difference :))
We need something better to alert us, before failure strikes 🙂
thx man
If anybody stumbles this , here’s the update:
smartctl will show you proper results for SSD SMART status.
Great info on https://www.virten.net/2016/05/determine-tbw-from-ssds-with-s-m-a-r-t-values-in-esxi-smartctl/
some1 ported smartctl and this is the best solution to get SMART data in esxi:
http://www.virten.net/2016/05/determine-tbw-from-ssds-with-s-m-a-r-t-values-in-esxi-smartctl