
{kind=link}
Today we'll cover another objective from VCP-DCV 2019 certification and we'll talk about VMware clusters. Chapter after chapter we're getting closer to fill the blueprint objectives and help students to study and pass the Professional vSphere 6.7 Exam 2019. Today's chapter: Objective 1.9 – Describe the purpose of a cluster and the features it provides.
A cluster is basically a group of hosts where are managed the resources of all hosts within it. When a host is added to a cluster, the host's resources become part of the cluster's resources. Clusters enable the vSphere High Availability (HA) and vSphere Distributed Resource Scheduler (DRS) solutions.
We basically cover what we think that’s important for each chapter since there are no special guidelines and sub-chapters like in the VCP6.5-DCV Study Guide. As such, you should not rely on our information only. Perhaps it is also a good idea to download the older VCP6.5-DCV study guide PDF as the structure of each chapter is much more detailed and IMHO gives better support to study.
In order to become VCP-DCV 2019 certified and pass the Professional vSphere 6.7 exam, we follow are the guidelines from the VMware Exam blueprint 2V0-21.19..
Check out: VMware Certification Changes in 2019. No mandatory recertification after 2 years. Older certification holders (up to VCP5) can pass the new exam without a mandatory course, only recommended courses are listed).
The Professional vSphere 6.7 Exam 2019 (2V0-21.19) which leads to VMware Certified Professional – Data Center Virtualization 2019 (VCP-DCV 2019) certification is:
- A 70-item exam
- Passing score of 300 using a scaled scoring method.
- Candidates are given 115 minutes to complete the exam
You don't have to pass the latest exam to become VCP-DCV 2019 certified. Did you know?
To become VCP-DCV 2019 certified you have 3 different choices of exam:
- Professional vSphere 6.7 Exam 2019
- VMware Certified Professional 6.5 – Data Center Virtualization exam (our VCP6.5-DCV Study Guide Page which is complete)
- VMware Certified Professional 6.5 – Data Center Virtualization Delta exam
Note: You must be VCP5, or VCP6. If, not, you must “sit” a class and you have no “Delta” exam option.
This guide is available as Free PDF!
Free Download at Nakivo – VCP6.7-DCV Study Guide.

VCP-DCV 2019 Study Guide
VCP6.7-DCV Objective 1.9 – Describe the purpose of cluster and the features it provides
As we said, a cluster is created at the datacenter level. One vCenter can manage several datacenters, and inside of each datacenter you can have several clusters, each actif with different services (DRS, HA, VSAN …. ).
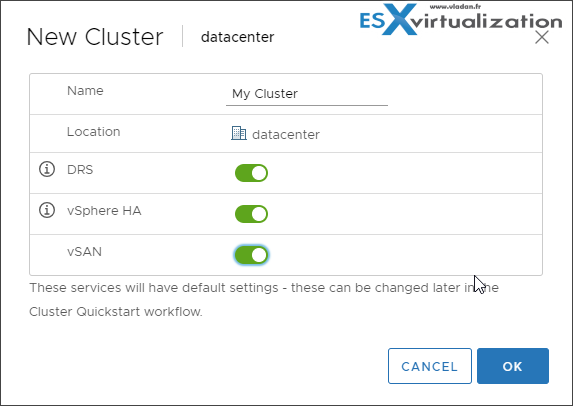
Nowadays, it's quite easy to configure VMware cluster.
VMware High Availability (HA)
VMware HA continuously monitors all servers in a resource pool and detects server failures. An agent placed on each server maintains a “heartbeat” with the other servers in the resource pool and a loss of “heartbeat” initiates the restart process of all affected virtual machines on other servers.
VMware HA makes sure that sufficient resources are available in the resource pool at all times to be able to restart virtual machines on different physical servers in the event of server failure. Restart of virtual machines is made possible by the Virtual Machine File System (VMFS) clustered file system which gives multiple ESXi Server instances read-write access to the same virtual machine files, concurrently.
VMware HA is easily configured for a resource pool through vCenter.
Key Features of VMware HA
- Automatic detection of server failures. Automate the monitoring of physical server availability. HA detects server failures and initiates the virtual machine restart without any human intervention.
- Resource checks. Ensure that capacity is always available in order to restart all virtual machines affected by server failure. HA continuously monitors capacity utilization and “reserves” spare
capacity to be able to restart virtual machines.
VMware High Availability (HA) provides easy to use, cost-effective high availability for applications running in virtual machines. In the event of server failure, affected virtual machines are automatically restarted on other production servers with spare capacity.
By activating HA, you basically minimize downtime and IT service disruption while eliminating the need for dedicated stand-by hardware and installation of additional software. You also provide uniform high availability across the entire virtualized IT environment without the cost and complexity of failover solutions tied to either operating systems or specific applications.
How HA works?
When you create a vSphere HA cluster, a single host is automatically elected as the master host. The master host communicates with vCenter Server and monitors the state of all protected virtual machines and of the slave hosts.
When you add a host to a vSphere HA cluster, an agent is uploaded to the host and configured to communicate with other agents in the cluster. Each host in the cluster functions as a master host or a subordinate host (often called “slave”).
HA protects against downtime. Which kind of problems are you protected from?
In a vSphere HA cluster, three types of host failure are detected:
- Failure – A host stops functioning.
- Isolation – A host becomes network isolated.
- Partition – A host loses network connectivity with the master host.
This communication happens through the exchange of network heartbeats every second. When the master host stops receiving these heartbeats from a subordinate host, it checks for host liveness before declaring the host failed. The liveness check that the master host performs is to determine whether the subordinate host is exchanging heartbeats with one of the datastores. See Datastore Heartbeating. Also, the master host checks whether the host responds to ICMP pings sent to its management IP addresses.
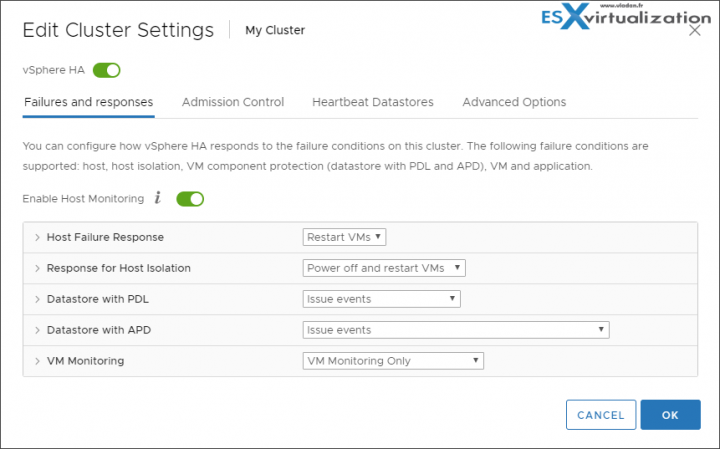
Failures and responses – you can configure how vSphere HA responds to failure conditions on a cluster. There are 4 failure conditions:
- Host – allows you to configure host monitoring and failover on the cluster. (“Disabled” or “Restart VMs” – VMs will be restarted in the order determined by their restart priority).
- Host Isolation – allows you to configure the cluster to respond to host network isolation failures:
- Disabled – No action will be taken on the affected VMs.
- Shut down and restart VMs – All affected VMs will be gracefully shutdown and vSphere HA will attempt to restart the VMs on other hosts online within the cluster.
- Power Off and Restart VMs – All affected VMs will be powered Off and vSphere HA will attempt to restart the VMs on the hosts which are still online.
- VM component protection – datastore with Permanent Device Lost (PDL) and All paths down (APD):
- Datastore with PDL – allows you to configure the cluster to respond to PDL datastore failures.
- Disabled – no action will be taken to the affected VMs.
- Issue events – no action to the affected VMs. Events will be generated only.
- Power Off and restart VMs – All affected VMs will be terminated and vSphere HA will attempt to restart the VMs on hosts that still have connectivity to the datastore.
- Datastore with APD – allows you to configure the cluster to APD datastore failures.
- Disabled – no action will be taken to the affected VMs.
- Issue Events – no action to the affected VMs. Events will be generated only.
- Power Off and restart VMs – All affected VMs will be terminated and vSphere HA will attempt to restart the VMs if another host has connectivity to the datastore.
- Power Off and restart VMs – Aggressive restart policy – All affected VMs will be powered Off and vSphere HA will always attempt to restart VMs.
- Datastore with PDL – allows you to configure the cluster to respond to PDL datastore failures.
- VM and application monitoring – VM monitoring hard restarts of individual VMs if their VM tools heartbeats are not received within a certain time. Application monitoring resets individual VMs if their in-guest heartbeats are not received within a set time.
Admission Control
Admission control is a policy which is used by vSphere HA to make sure that there is enough failover capacity within a cluster.
- Cluster resource Percentage (default) – The configuring workflow for admission control is a little bit simpler. You first define a parameter how many failed hosts you want to tolerate within your cluster, and the system will do the math for you. As default HA cluster admission policy, VMware will use the cluster resource Percentage now. (previously host failures the cluster tolerates policy, was used).
- Override Possible – You can override the default CPU and memory settings if needed. (25% as in previous releases).
Performance degradation Warning message – Previously HA could restart VM, but those would suffer from performance degradation. Now you have a warning message which informs you about it. You’ll be warned if performance degradation would occur after an HA even for a particular VM(s).
0% – Raises a warning if there is insufficient failover capacity to guarantee the same performance after VMs restart.
100% – Warning is disabled
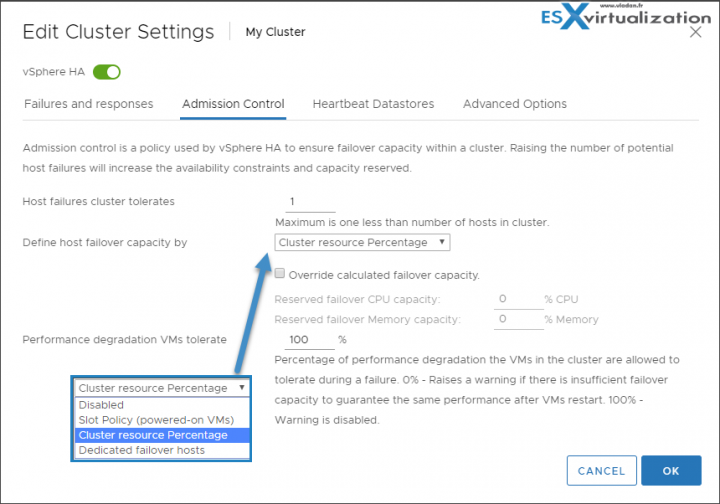
Other then cluster resource percentage policy there are “Slot policy” and “Dedicated failover host” policies.
- Slot policy – the slot size is defined as the memory and CPU resources that satisfy the reservation requirements for any powered-on VMs in the cluster.
- Dedicated Failover Host – You pick a dedicated host which comes into a play when there is a host failure. This host is a “spare” so it does not have running VMs during normal operations. Waste of resources.
Enable/disable vSphere HA settings
To enable vSphere HA, open vSphere Client > Select cluster > Configure > vSphere Availability > Click Edit button.
vSphere DRS
VMware vSphere Distributed Resource Scheduler (DRS) is a resource scheduler. It monitors and it can react to changes in VM workloads. The system can migrate VMs to other hosts in order to distribute the load.
DRS automatically places virtual machines onto hosts at VM power-on, and virtual machines are automatically migrated from one host to another to optimize resource utilization.
DRS affinity rules
You can control the placement of virtual machines on hosts within a cluster by using affinity rules. Certainly useful if you want (or not) that two or more VMs runs on the same host(s).
You can create two types of rules.
VM-Host affinity rule – specifies an affinity relationship between a group of virtual machines and a group of hosts. There are ‘required‘ rules (designated by “must“) and ‘preferential’ rules (designated by “should“.)
An affinity rule specifies that the members of a selected virtual machine DRS group can or must run on the members of a specific host DRS group. An anti-affinity rule specifies that the members of a selected virtual machine DRS group cannot run on the members of a specific host DRS group.
A VM-Host affinity rule includes the following components:
- One virtual machine DRS group.
- One host DRS group.
VM-VM affinity rule – Whether VMs should run on the same host or be kept on separate hosts.
With an anti-affinity rule, DRS tries to keep the specified virtual machines apart. You could use such a rule if you want to guarantee that certain virtual machines are always on different physical hosts. In that case, if a problem occurs with one host, not all virtual machines would be placed at risk.
A rule specifying affinity causes DRS to try to keep the specified virtual machines together on the same host, for example, for performance reasons. With an anti-affinity rule, DRS tries to keep the specified virtual machines apart, for example, so that when a problem occurs with one host, you do not lose both virtual machines.
When you add or edit an affinity rule, and the cluster’s current state is in violation of the rule, the system continues to operate and tries to correct the violation. For manual and partially automated DRS clusters, migration recommendations based on rule fulfillment and load balancing are presented for approval. You are not required to fulfill the rules, but the corresponding recommendations remain until the rules are fulfilled.
To check whether any enabled affinity rules are being violated and cannot be corrected by DRS, select the cluster’s DRS tab and click Faults. Any rule currently being violated has a corresponding fault on this page. Read the fault to determine why DRS is not able to satisfy the particular rule. Rules violations also produce a log event.
Starting vSphere 6.5, DRS no takes into consideration also the network utilization. It takes into account the network utilization of host and network usage requirements of VMs during initial placement and load balancing. As a result, load balancing and DRS is more “intelligent”.
DRS does the initial placement in two steps:
- It compiles the list of possible hosts based on cluster constraints and compute resource availability and ranks them.
- Then, from the list of hosts, it picks the host with the best rank and best network resource availability
Predictive DRS
Predictive DRS happens when vCenter server proactively rebalances the VMs based on predictive patterns in the cluster workload. Predictive DRS bases its data provide by vRealize Operations Manager. vROPS monitor VMs running within a vCenter server and analyzes the historical data. Based on this, it can forecast data, predictable patterns of resources usage. Those data are used by predictive DRS, which moves VMs around based on the patters.
Follow the progress of the VCP6.7-DCV Study Guide page for further updates.
More from ESX Virtualization
- What is VMware vCenter Convergence Tool?
- What is VMware Platform Service Controller (PSC)?
- What is vCenter Embedded Linked Mode in vSphere 6.7?
- VMware vExpert 2019 – This is vExpert x11
- How To Reset ESXi Root Password via Microsoft AD
- How to Patch VMware vCenter Server Appliance (VCSA) 6.7 Offline
Stay tuned through RSS, and social media channels (Twitter, FB, YouTube)