
{kind=link}
Windows Server 2016 will also have a new deduplication engine. In this post, we will have a look on how to setup data deduplication in Windows Server 2016 and also what's changes compared to 2012 R2. While 2012R2 the recommended size of volumes suitable for deduplication were limited to 10 Tb, with the upcoming Windows Server 2016 and multi-threaded processing, volumes with sizes up to 64 Tb can be used for deduplication.
Data deduplication is not supported for certain volumes, such as any volume that is not a NTFS file system or any volume that is smaller than 2 GB. This post is based on latest Windows Server 2016 TP5 available for download here.
But first, let me explain in few words for folks which do not know what is deduplication. The deduplication can be defined like this:
By using deduplication, you can store more data in less space by segmenting files into small variable-sized chunks (32–128 KB), identifying duplicate chunks, and maintaining a single copy of each chunk. Redundant copies of the chunk are replaced by a reference to the single copy. The chunks are compressed and then organized into special container files in the System Volume Information folder.
How to configure data deduplication in Windows Server 2016?
Step 1: Open Server manager and Add the Server Role (it's not installed after a fresh server installation even if the Storage services are).
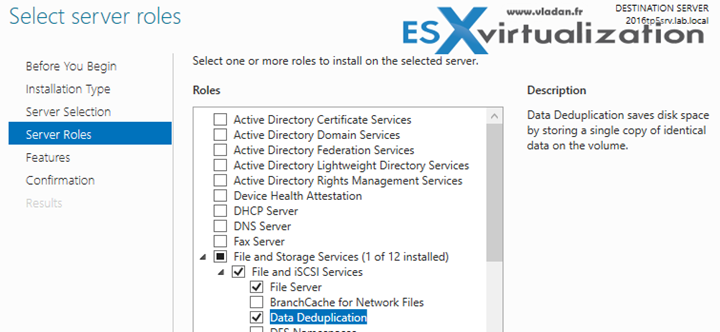
Step 2: Go to File and Storage Services to find a disk (or better say volume) suitable for deduplication.
First click on a disk and format it with NTSF file system.
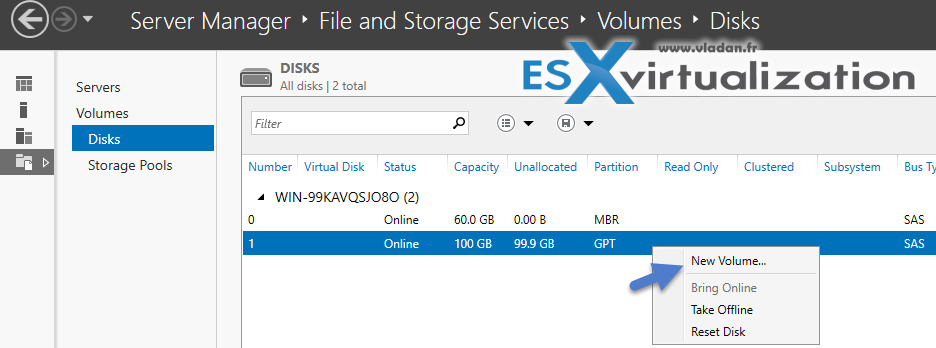
Usual operation. Nothing unusual here. Previous versions of Windows server systems were pretty much the same…
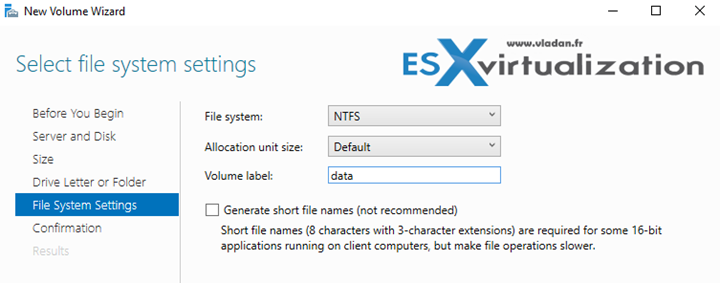
Note that during the volume creation wizard you actually get a page where you can activate deduplication, but in this guide I'm showing how to configure deduplication on a volume which does not have the deduplication activated yet, but it's already formatted with an NTFS file system.
Step 3: Click on Volumes and select a volume where you want to setup the data deduplication.
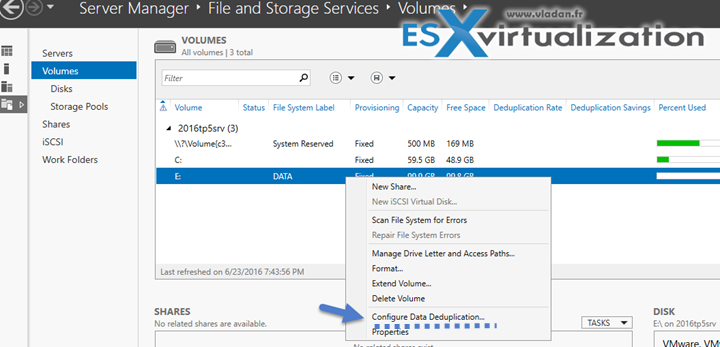
Then from the drop-down menu > select the purpose of the volume and the deduplication type….
You can also add custom file extensions you want to exclude there.
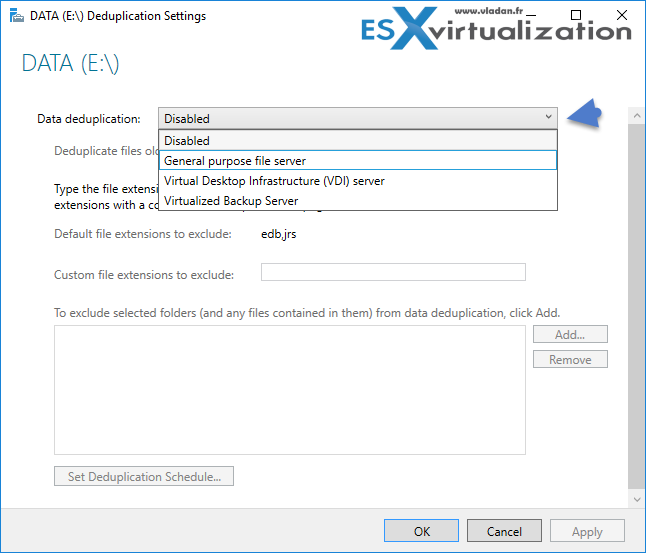
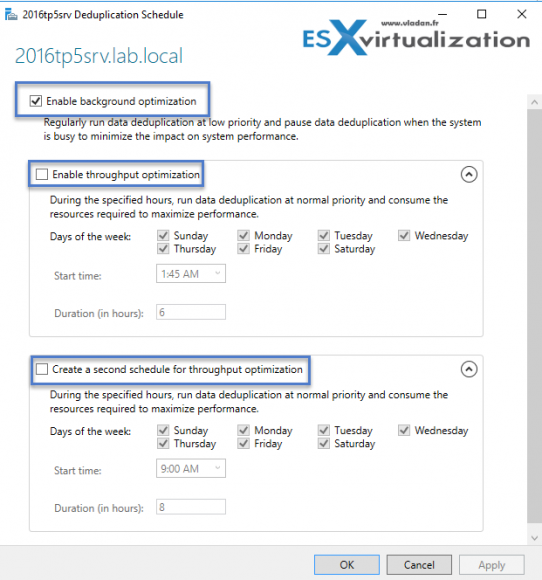
By clicking the Set Deduplication Schedule button you'll be able to:
- Enable Background Optimization
- 1st and 2nd deduplication runs. Bear in mind that those two schedules will use CPU cycles and consume ressources so it's preferable to set those outside of business hours and outside of backup window too…
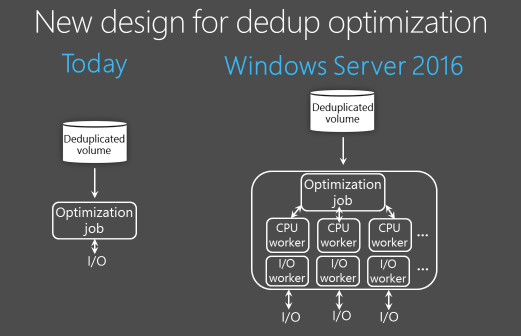
Data deduplication uses subfile variable-size chunking and compression, which deliver optimization ratios of 2:1 for general file servers and up to 20:1 for virtualization data.
Compared to Windows Server 2012 R2, it uses single threaded jobs and I/O queues. That all changes in Windows Server 2016 with a full redesign of deduplication and optimization processing. It does runs multiple threads in parallel using multiple I/O queues on a single volume, resulting in performance that was only possible before by dividing up your data into multiple, smaller volumes. (10Tb recommended).
Wrap-up
I just scratched a surface with this post. I know. There are other options, with PowerShell. There is also a PowerShell cmdlet which allows activating the deduplication via PowerShell. It is certainly a very good improvement over the 2012R2 server but only for customers needed to use this technique on really big volumes.
Stay tuned for more…
Source: Technet
Hi Vladan,
May I know what does it means by “10Tb recommended”, is that the maximum Deduped File Server volume in Windows Server 2016 ?