
{kind=link}
VMware SRM & HP P4000 VSA Intricacies
This is a guest post by Andy Grant.
I have a bad habit of standing up a solution in my home lab, only to tear it down shortly afterwards to play with something new. I have been using EMC's UBER line of virtual storage appliances (VSAs) for my VMware SRM testing. Earlier Celerra based editions provide iSCSI and NFS with the current VNX line only offering NFS support. I applaud Nick for his efforts providing this superb community resource.
If you have used Site Recovery Manager in an enterprise environment, you will know that the big difference between installations is going to be the configuration of your SRA (storage replication adapter). Between Hitachi Horcm files and EMC SrdfSraOptions, the key to success will be the integrate between SRM and the storage replication.
Looking for a little diversity in my lab I decided to download and install HP's P4000 VSA available as a free download with a 60 day trial of the replication and clustering features. In contrast to the UBER line of VSA's, the P4000 VSA is a light-weight, offering exceptional performance using only 1Gb RAM and no special tweaks, not even Jumbo Frames 😯 .
Download and installation is a snap, deploying two of them using seperate “management groups” allows you to create a scheduled Remote Copy between “sites” that SRM will recognize.
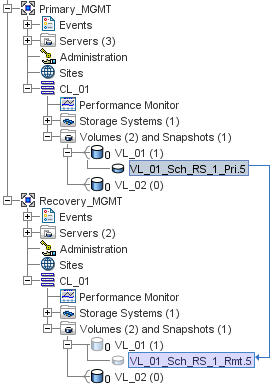 Here I have my two management groups , Primary_MGMT and Recovery_MGMT, that represent my two sites containing P4000 VSA's.
Here I have my two management groups , Primary_MGMT and Recovery_MGMT, that represent my two sites containing P4000 VSA's.
I setup my first volume (VL_01) to copy between sites using the minimum available time interval of 30 minutes. The P4000 replicates snapshots between sites and you can store multiple snapshots at each site for quick-restore purposes. Due to the long interval between snapshots, your RPO (Recovery Point Objective), ie “data loss,” in a true DR situation puts this solutions squarely mid-tier compared to other a/sync solutions. The P4000 does support multi-site clustering, but this falls more in line with a HA solution or perhaps disaster avoidance, not a traditional DR solution.
Having successfully setup SRM environments many times before this looked to be a simple and quick solution to deploy. Or so I thought..
The single most beneficial feature provided by SRM is the ability to perform a “Test” Recovery to validate your DR plans. Naturally, anyone who has used it before, this is the first thing you do to validate your configuration.
Unfortunately I would encounter a problem during the Recovery Step “Prepare Storage” of a Test or Actual Recovery, the failure was a rather mystifying error.
![]()
Somehow the SRA is smart enough to know that the server already exists, but not smart enough to use the existing configuration entry.
The Recovery Site P4000 VSA does not present a Read-Only copy of the replicated LUN like you might experience with a FC solution; or even the UBER VSA on NFS. Only during a Test or Actual recovery does the P4000 present a snapshot to the recovery host(s). It is this behavior that is causing the error since a target host can only be presented by the P4000 once, and I am already presenting a non-replicated iSCSI target to store the placeholder VM's on VL_02 (shown in red).
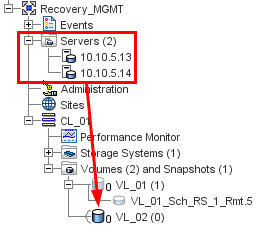
With that said, the troubleshooting began; reviewing SRM logs, reinstalling the SRA's, redeploying the P4000's, search forums; all to no avail. There was little evidence to support what the root cause of the fault may be. After contacting a few LeftHand personnel, they confirmed this was not normal behavior and not a common error. Without a support contract I could not go further up the official support chain and would have to continue troubleshooting on my own.
I have seen the same configuration that I am using work correctly in other environments so I knew it could work and I only had to uncover the difference. Without having access to these other environments would mean that I needed to evaluate all components.
After much tribulation, I came to conclude that the P4000 SRA must not be able to properly identify that I have already presented LUN's to the hosts when SRM triggers it to present the replicated snapshot. Unfortunately I was still stumped as to why this was.
I stumbled upon the VMware communities post Test Failover Fails that does not address the same problem, but got me thinking; perhaps I am dealing with an IQN issue. After all, the SRA is supposed to check for an existing server entry and use that if the server has other LUN's presented. I am using the latest SRA available v9.0.0.3561.
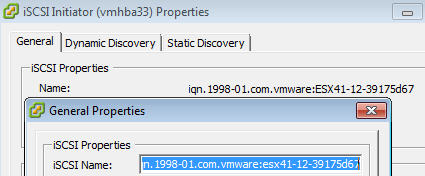 Whenever creating a new server entry in the P4000 CMC, I would copy and paste the name found in the adapter properties using the vSphere client. This has always worked to present hosts so I never thought twice about this strategy. I have never needed to change the IQN from the default self-generated one provided so why start now. But perhaps there is more to this and perhaps vSphere and the SRA abide by different rules.
Whenever creating a new server entry in the P4000 CMC, I would copy and paste the name found in the adapter properties using the vSphere client. This has always worked to present hosts so I never thought twice about this strategy. I have never needed to change the IQN from the default self-generated one provided so why start now. But perhaps there is more to this and perhaps vSphere and the SRA abide by different rules.
As you can tell from the screenshot above, depending on where you copy the IQN string from, you may get a slightly different version. I like to click the “Configure” button in the adapter properties to copy a lower-case version of the IQN even though you can see that my hostname “ESXi41” has capital letters in it.
The CMC does not accept upper-case letters.
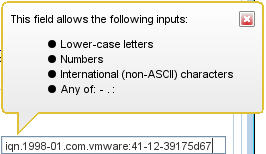 So I tried manually changing my IQN to remove the any upper-case letters in the hostname portion of the IQN to lower-case values. The next time I triggered a Test Recovery, low and behold it worked !! Boy was I smiling.
So I tried manually changing my IQN to remove the any upper-case letters in the hostname portion of the IQN to lower-case values. The next time I triggered a Test Recovery, low and behold it worked !! Boy was I smiling.
To summarize: be sure that your hosts IQN contains only lower-case values when using HP P4000 storage and Site Recovery Manager to automate your DR plans.
I can't say that I am overly surprised at this, what I am surprised at is the lack of clear information on the topic. If any of you know if this is documented somewhere please leave a comment below.
On a side-note, I did experience a similar peculiarity using the EMC UBER line of VSA's. I had problems setting up replication when using a hyphen in the hostname. Although I must admit, I was able to find the solution within a few minutes of Googling 🙄