I finally got to meet the great Chris Wahl. This guy is a very smart guy, and now he joined Rubrik, which is also full of smart folks working there. My first contact with Rubrik was during #VFD5 in Boston few months back. Check out the post – Rubrik Data Management – New Aproach For VMware Backups?
Their cloud file system spanning on-premise and cloud environment is kind of new in this field. It can scale out linear way, if needed by adding additional nodes, without interruption or reconfiguration of existing backup architecture. New nodes are discovered automatically. Coupled with hardware appliance which setup is easy, their solution shall interest clients seeking at the same time a robust and simple backup solution as well as hardware to install it to. They'll get at the same time the capacity and also the computing power with “all smart sauce” in between…
Because at the end of the day, you might end-up in a situation where you don't want to use storage space of your principal array for store backups as well. Rubrik has ultra efficient and scalable storage appliance with integrated backup capabilities which is simple to manage, based on SLAs concerning backup snapshots frequency and data retention policy.
Hardware and Software, all bundled in. All data are deduplicated, compressed before written to storage. Efficiency seems to be one of the keys which by using global deduplication, allows to maximize the capacity savings across the stack.
Here is the video from VMworld Barcelona. Few questions about Rubrik and the roadmap:
Rubrik in details:
Rubrik Cloud-Scale File System is a distributed file system allows to manage versioned data. The filesystem is fault tolerant allowing to lose multiple node and disk failures and still remain operational. Multiple copies are distributed through the cluster.
- Distributed file system – stores and manages versioned data. Everything is written to flash firs, then destaged to spinning media.
- Distributed metadata service – provides a scale-out index of metadata across a cluster of Rubrik appliances. New nodes are discovered automatically by using Zeroconf multicast DNS, similarly like EVO: RAIL does)
- Distributed task scheduler – backs up data, index the data, updating the distributed metadata servie and replicate the data elsewhere to provide resiliency.
- Clustering
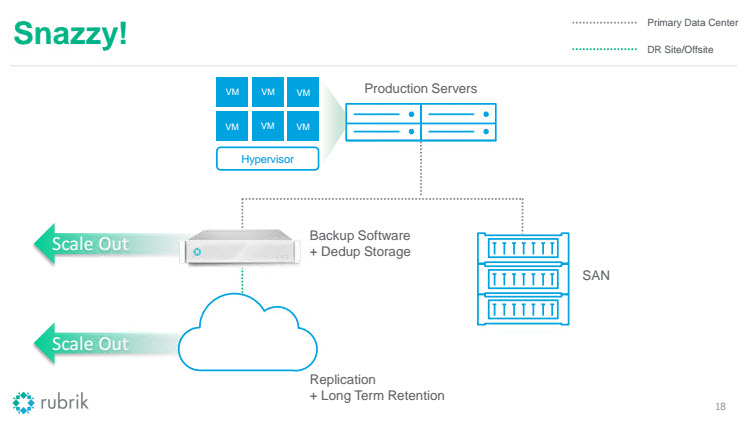
Check my previous post in more details from#VFD5 here.

{kind=link}